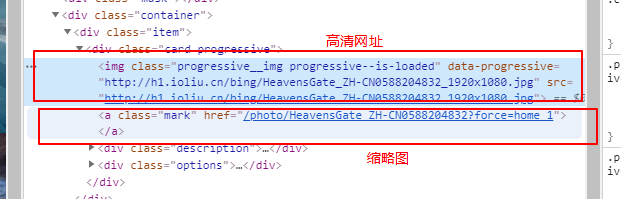
Bing上有很多精美的图片,可以利用python将这些图片抓取下来作为电脑的壁纸。想要抓取Bing上的高清图,首先需要对Bing图片展示的源代码进行分析,可以确定非贪婪匹配字段为(非贪婪算法可参考):
1
| pic_urls_match = r'data-progressive=\"(.*?)\"'
|
通过以下代码可以实现对网页的获取,具体原理我会在其他文章中介绍
1
2
3
4
5
6
7
8
| def getPage(url):
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html_code = res.read().decode('UTF-8')
return html_code
|
设置图片保存函数,其中使用try是为了在图片抓取的过程中,某一张图片获取失败不影响其他图片的抓取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def saveImg(img_url,dirname):
try:
if not os.path.exists(dirname):
print ('文件夹',dirname,'不存在,重新建立')
os.makedirs(dirname)
basename = os.path.basename(img_url)
filepath = os.path.join(dirname, basename)
urllib.request.urlretrieve(img_url,filepath)
print("Save", filepath, "successfully!")
except IOError as e:
print ('文件操作失败',e)
except Exception as e:
print ('错误 :',e)
return filepath
|
主函数
1
2
3
4
5
6
7
8
9
10
11
| def main():
url = 'https://bing.ioliu.cn/'
html_code = getPage(url)
pic_urls_match = r'data-progressive=\"(.*?)\"'
image_urls = re.findall(pic_urls_match,html_code)
for i in range (len(image_urls)):
img_url = image_urls[i]
filepath = saveImg(img_url,'C:\\Users\\***\\Desktop\\srceen')
print('Compelet')
|
最后的图片展示,所有的源代码可以在我的Github上找到
