#定义激活函数 defget_act(x): act_vec = [] for i in x: act_vec.append(1/(1+math.exp(-i))) act_vec = np.array(act_vec) return act_vec
defget_err(e): return0.5*np.dot(e,e)
# 训练——可使用err_th与get_err() 配合,提前结束训练过程
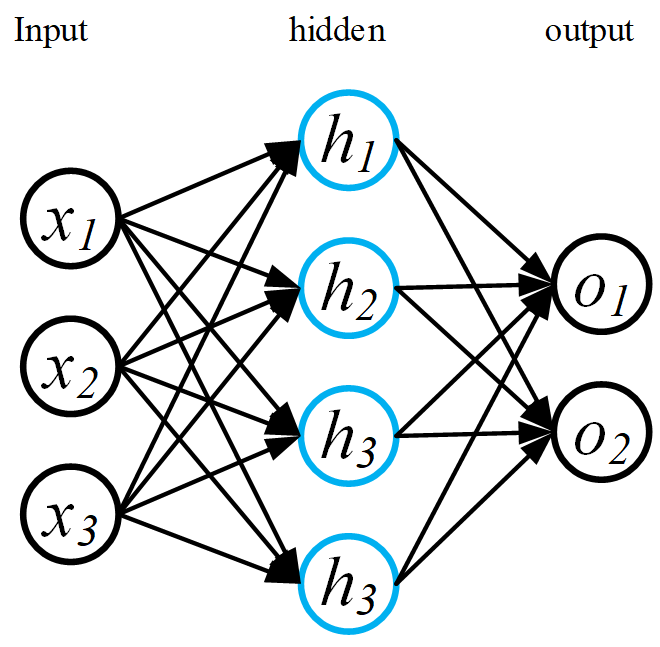
for count in range (0,dataset_num): t_label = np.zeros(out_num) t_label[dataset_label[count]] = 1 #前向过程 hid_value = np.dot(dataset[count],w12) hid_act = get_act(hid_value) out_value = np.dot(hid_act,w23) out_act = get_act(out_value)
#反向过程 e = t_label - out_act out_delta = e*out_act*(1-out_act) hid_delta = hid_act * (1-hid_act)*np.dot(w23,out_delta) for i in range(0,out_num): #更新隐藏层到输出层权向量 w23[:,i] += hid_learnrate * out_delta[i] * hid_act for i in range (0,hid_num): #更新输入层到隐藏层权重 w12[:,i] += input_learnrate * hid_delta[i] * dataset[count]